

SUMMARY
- Le suivi côté serveur envoie des données directement du serveur de votre site Web aux plateformes MarTech, sans passer par les navigateurs. Cette solution garantit une meilleure précision et gouvernance des données, ainsi qu’une sécurité accrue, mais exige en même temps un effort de développement important.
- Le balisage côté serveur repose sur un serveur dédié de gestion des balises pour traiter les données, ce qui permet un meilleur contrôle et respect de confidentialité. En même temps, la méthode nécessite des efforts importants en matière de mise en place et de maintenance.
- La configuration hybride côté serveur, connue grâce à des outils tels que Google Tag Manager et Google Analytics 4, partage certains avantages de la méthode de suivi pur côté serveur et est plus facile à utiliser grâce à une configuration côté client plus flexible.
- Bien que le suivi et le balisage côté serveur renforcent la fiabilité des données et permettent de contourner certaines limitations côté client, ceux-ci ne doivent pas être utilisés sans le consentement du visiteur.
Depuis des années, les entreprises utilisent des balises et des pixels côté client pour suivre les visiteurs d’un site web, améliorer l’expérience utilisateur, mesurer les taux de conversion et personnaliser les publicités. Toutefois, l’essor des bloqueurs de publicité et la prise en charge limitée du suivi tiers dans les navigateurs rendent les méthodes côté client plus difficiles à mettre en œuvre. Les entreprises à la recherche de données précises sur le comportement utilisateur explorent des alternatives, la collecte de données côté serveur se présentant comme une possible solution à leurs problèmes.
Cela dit, les méthodes côté serveur peuvent prêter à confusion au vu des différentes formes qu’elles peuvent adopter. Dans cet article nous visons à dissiper les idées reçues sur la collecte de données côté serveur et à clarifier les différences entre les méthodes de suivi.
A noter : Pour des raisons de clarté, dans cet article, nous désignons les méthodes reposant à la fois sur des composants côté client et côté serveur en tant que suivi et/ou balisage hybride côté serveur. En même temps, les méthodes reposant entièrement sur une configuration côté serveur seront appelées le suivi et/ou balisage pur côté serveur.
Qu’est-ce que le suivi côté serveur ?
Pour expliquer les mécanismes du suivi côté serveur, comparons-les d’abord à l’implémentation par défaut du suivi côté client.
Qu’est-ce que le suivi côté client ?
Le suivi côté client recueille des données en envoyant des informations du navigateur de l’utilisateur (le client) directement à un serveur externe, comme votre compte d’analyse (par exemple, votre site web.piwik.pro). Pour ce faire, il suffit d’ajouter de petits morceaux de code JavaScript, appelés balises, à chaque page de votre site web. Celles-ci sont généralement gérées via un système de gestion des balises.
Dans le cas du suivi côté serveur, en revanche, l’envoi des demandes de suivi et la collecte des données s’effectuent sur le serveur, sans l’intervention du navigateur. Les données sont ensuite envoyées du serveur vers un outil de votre choix, tel que votre plateforme d’analyse, afin d’alimenter vos rapports et tableaux de bord.
Méthodes de collecte de données côté serveur
Bien que le concept de suivi côté serveur puisse paraître nouveau, celui-ci remonte aux débuts des années 1990 et aux origines de l’analyse Web. Connue sous le nom d’analyse des journaux, la méthode consistait à récupérer les fichiers journaux d’accès à partir des serveurs du site Web de l’entreprise. Ainsi, les spécialistes du marketing disposaient des informations de base sur les visiteurs de leur site Web, telles que l’emplacement, le dispositif, le site de référence et le navigateur. Bien que complexe et fastidieuse, cette méthode est préférable à l’absence totale de données.
Heureusement, le paysage analytique a depuis connu un développement important et les méthodes modernes d’analyse côté serveur offrent une bien meilleure convivialité et qualité de données.
Déploiement de suivi pur côté serveur
Une mise en œuvre côté serveur moderne consiste typiquement à la collecte de toutes les données en dehors du navigateur. La communication s’effectue directement entre le serveur d’un site web et une plateforme de marketing (un outil d’analyse).
L’intégration entre votre serveur de site Web et une plateforme marketing se fait généralement à l’aide de kits de développement logiciel (SDK) et d’interfaces de programmation d’applications (API). Ces dernières permettent à votre serveur d’envoyer des données à la plateforme marketing, tandis que les SDK facilitent la création de ces requêtes API à l’aide de fonctions prédéfinies.
Cette méthode permet de mieux contrôler la collecte et le traitement des données ainsi que d’améliorer la sécurité en supprimant l’impact du déploiement côté client. Vous disposez également de liberté totale au niveau du choix d’identificateur utilisateur que vous souhaitez utiliser – cookies, empreintes digitales, etc.
Enfin, cela permet de combiner des données provenant de différentes sources, ce qui enrichit la collecte globale de données.
Toutefois, la mise en œuvre de ce type de suivi nécessitant une configuration complexe et un effort de développement important, cette approche serait mieux adaptée aux entreprises disposant d’une équipe de développement plus nombreuse et plus avancée.
Avantages du suivi analytique pur côté serveur
Précision des données et longévité des cookies
Cette méthode réduit la perte de données subie avec les trackers côté client, peut prolonger la durée de vie des cookies et contourner les limitations côté client. Résultat ? Des données plus fiables et plus complètes. Le suivi étant entièrement basé sur une configuration côté serveur, il fournit des données de la plus haute qualité par rapport à d’autres méthodes modernes côté serveur.
Gouvernance des données
Le suivi pur côté serveur favorise un meilleur contrôle des données, garantissant que seules les données nécessaires sont collectées et que la plupart des types d’informations sensibles ne sont pas partagées dans le navigateur. Cela dit, il est quand même possible que vous ayez besoin d’un identifiant personnel, par exemple celui d’un cookie de visiteur, pour reconnaître les visiteurs d’une session à l’autre.
Sécurité renforcée
Les données sensibles sont traitées de manière plus sûre sur le serveur, ce qui minimise le risque d’exposition du côté client.
Considérations importantes à l’égard du suivi côté serveur
RGPD et exigences de consentement
Il est important de souligner que le fait de déplacer votre suivi côté serveur ne rend pas votre collecte de données conforme à la protection de la vie privée. Vous êtes toujours tenu de respecter les mêmes règles que pour le suivi côté client : soit vous recueillez des consentements valides de la part des visiteurs, soit vous rendez vos données entièrement anonymes. De même, si vous décidez d’enrichir les données ou d’envoyer des données sur les conversions à différentes plateformes, vous aurez besoin d’un consentement distinct pour chacun de ces objectifs.
Effort de développement
La mise en œuvre du suivi côté serveur nécessite un effort de développement important. L’intégration de SDK ou d’API au serveur, la mise en place du traitement des données et la maintenance de l’infrastructure peuvent s’avérer complexes et chronophages. Les petites équipes ou organisations peuvent éprouver des difficultés à allouer les ressources nécessaires.
Coûts de serveur
La maintenance de l’infrastructure du serveur pour gérer le suivi côté serveur peut également s’avérer coûteuse. À mesure que les volumes de données augmentent, vous pouvez être amené à faire évoluer votre infrastructure de serveurs, ce qui peut encore accroître les coûts et la complexité.
Exemples d’outils pour le suivi pur côté serveur
- Piwik PRO Analytics Suite
- Matomo
- Google Analytics 4
- Toute autre plateforme d’analyse disposant d’API et de SDK.
Suivi hybride côté serveur avec un collecteur de première partie
Les méthodes hybrides de suivi côté serveur combinent la commodité de la collecte de données côté client avec le contrôle, la sécurité et la flexibilité du suivi côté serveur. Celles-ci présentent, toutefois, un léger handicap en termes de précision des données, puisqu’elles reposent encore en partie sur le navigateur. Cela n’empêche que les méthodes hybrides ne soient bien plus fiables qu’une configuration reposant entièrement sur le côté client.
Dans le cadre du suivi côté serveur avec un collecteur de première partie, les données sont envoyées à un outil principal, généralement une plateforme d’analyse. Les demandes de suivi adressées au navigateur proviennent du domaine (ou sous-domaine) de votre site web et non d’une plateforme tierce. Les données passent ensuite par un serveur proxy sur votre serveur web avant d’atteindre la plateforme d’analyse.
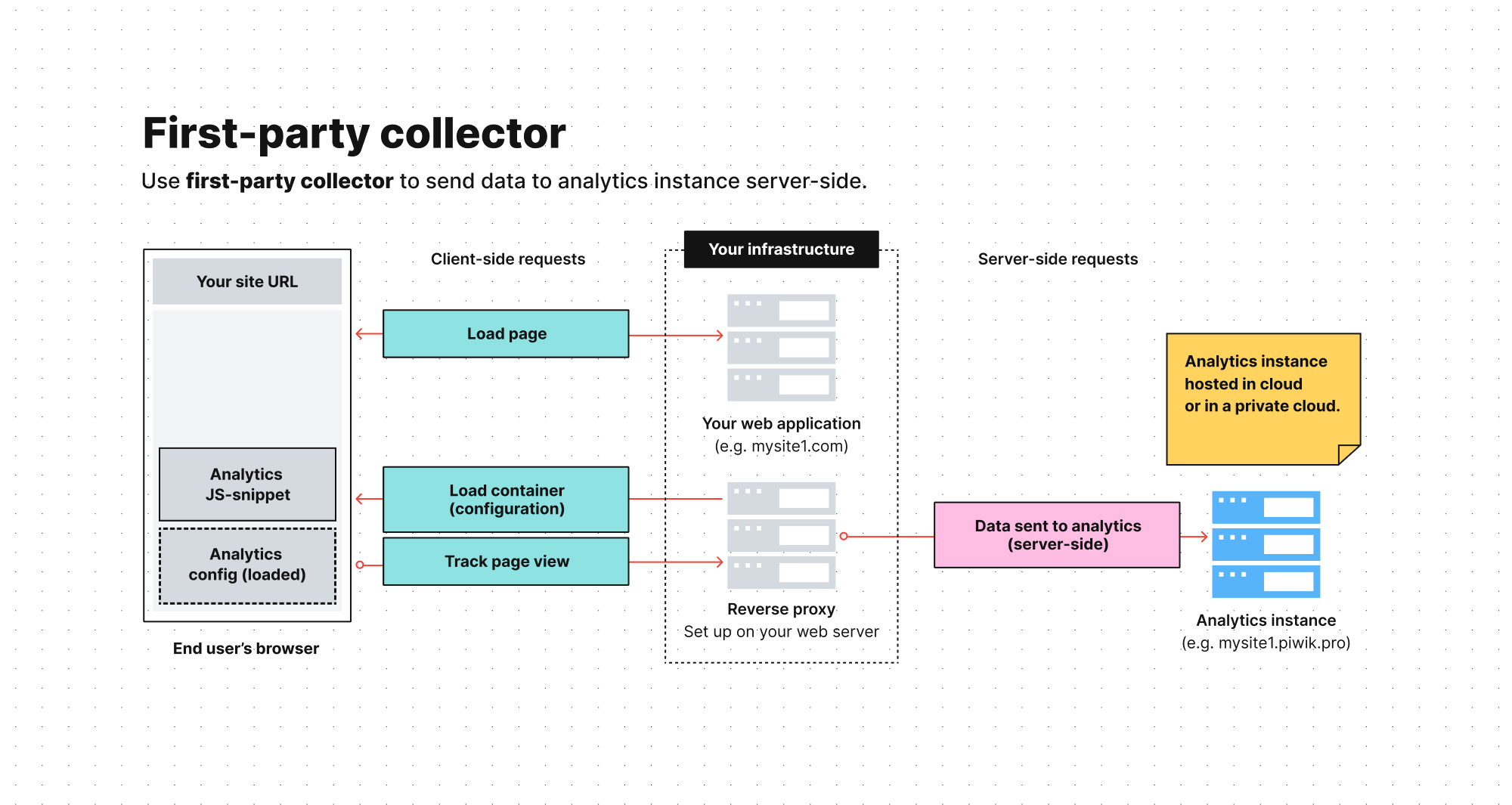
Étant donné que les demandes adressées aux navigateurs proviennent du même domaine et de la même adresse IP que les demandes nécessaires au chargement de votre page, la précision des données collectées augmente. Cette configuration peut notamment vous aider à booster la longévité de vos cookies et à éviter de nombreux problèmes envisageables dans une configuration côté client.
Un collecteur de première partie est également plus facile à gérer qu’une configuration pure côté serveur, car vous n’avez pas besoin d’intégrer une API ou d’utiliser d’autres méthodes d’intégration manuelles. Vous pouvez, en revanche, utiliser une solution prête à l’emploi développée par un fournisseur.
Avantages du suivi hybride côté serveur avec un collecteur de première partie
Meilleure précision des données et durée de vie des cookies augmentée
Cette méthode peut augmenter la durée de vie des cookies analytiques et optimiser la précision globale des données.
Commodité
Lorsque vous utilisez la méthode hybride avec un collecteur de première partie, vous bénéficiez de la souplesse de la configuration côté client ainsi que des possibilités offertes par le serveur. Par exemple, votre gestionnaire de balises côté client et votre consentement sont sur un domaine de première partie, ce qui les rend plus faciles à utiliser par rapport à d’autres méthodes côté serveur.
Collecte de données riche et de haute qualité
Le suivi hybride côté serveur fournit la même granularité de données que le suivi côté client, y compris les sources de trafic, les sites de référence, les pages vues, les parcours empruntés, les taux de conversion, les données en temps réel, les données du navigateur, la profondeur de défilement et les événements personnalisés.
Légèreté
La méthode réduit l’impact sur l’infrastructure car elle ne nécessite pas de plateforme séparée ou de déploiement de composants importants.
Indépendance des produits Google
Avec le suivi, vous n’avez plus besoin de faire recours au gestionnaire de balises côté serveur de Google ou d’impliquer ses serveurs. Cette indépendance est essentielle si vous souhaitez éviter les produits basés aux États-Unis en raison des problèmes de confidentialité et de transferts de données outre-Atlantique.
RGPD et exigence de consentement
Bien qu’il soit généralement indétectable dans les navigateurs, le suivi côté serveur nécessite toujours le consentement de l’utilisateur pour la collecte de données. Conformément aux normes du RGPD, les données ne peuvent être collectées sans consentement que si elles sont anonymisées. Cela dit, la collecte des consentements à l’aide d’un outil de première partie est beaucoup plus pratique qu’avec une solution pure côté serveur. La démarche peut être réalisée à l’aide d’une plateforme intégrée de gestion du consentement côté client qui permet d’ajuster le suivi de manière automatique aux préférences de confidentialité des visiteurs.

« Pour réaliser une mise en œuvre réussie du suivi côté serveur, il est crucial de choisir des outils internes de collecte de données conformes aux réglementations générales telles que le RGPD, le PECR ou le TTDSG. Plus sensibles sont les données que vous collectez (par exemple dans les secteurs bancaires, pharmaceutiques et gouvernementales), plus sélectif vous devriez être avec vos outils. »
Hamza El Kharraz
Digital Analyst chez ANALYGO
Exemples d’outils pour le suivi hybride côté serveur :
- Piwik PRO Analytics Suite
- Matomo
- Heap Analytics
- Adobe Analytics
- Google Analytics
- Segment
Considérations importantes pour le suivi côté serveur avec un outil de collecte first-party
Mise en œuvre complexe
Certes, réaliser le suivi à l’aide d’un collecteur de première partie semble moins complexe que l’analyse des journaux ou le suivi pur côté serveur, mais demande toujours du temps et des ressources. Si vous manquez d’expertise interne, envisagez d’opter pour une solution analytics avec un support et un service client dédiés. Cela vous permettra de démarrer avec votre activité et de maintenir votre paramétrage de suivi côté serveur.
Usage limité aux analyses
La méthode ne fonctionne que pour une seule partie de votre pile de données et bloque l’utilisation des balises tierces. Si vous souhaitez utiliser tous vos outils marketing côté serveur, pensez à incorporer d’autres méthodes telles que le balisage côté serveur.
Méthodes de balisage côté serveur
Une autre méthode prisée pour suivre les données côté serveur est le balisage.
Le balisage et le suivi côté serveur sont des concepts liés, mais servent à des fins différentes. Alors que le suivi côté serveur concerne principalement la collecte des données sur les interactions des utilisateurs avec un site Web directement via le serveur, le balisage côté serveur fait référence à l’implémentation et la gestion des balises de suivi (ces dernières ayant un objectif similaire à celui des scripts analytiques ou publicitaires) sur un serveur de gestionnaire de balises dédié.
A priori, la différence entre les deux est comparable à celle entre une plateforme d’analyse et un système de gestion de balises.
Balisage pur côté serveur
Avant d’expliquer le concept de balisage pur côté serveur, décrivons la mise en œuvre standard d’un gestionnaire de balises côté client.
Une configuration de balisage côté client typique repose sur des trackers installés directement sur la page. Ceux-ci envoient des données à divers serveurs de collecte, tels que vos analyses, votre outil de tests A/B ou votre CRM.
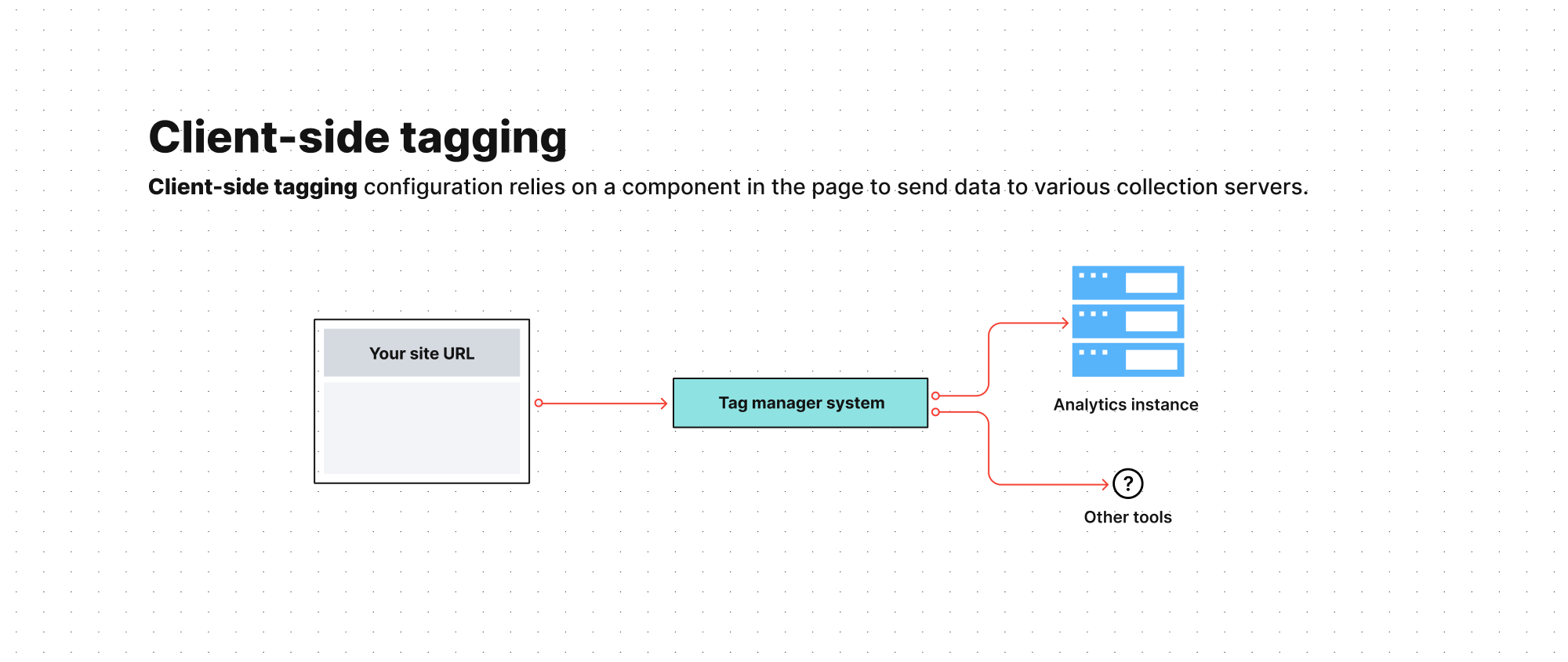
Contrairement au balisage côté client, le balisage côté serveur utilise un serveur de gestion de balises dédié pour héberger les données et les envoyer aux outils marketing. Cela crée un tampon séparant votre site Web et les données utilisateurs des fournisseurs tiers.
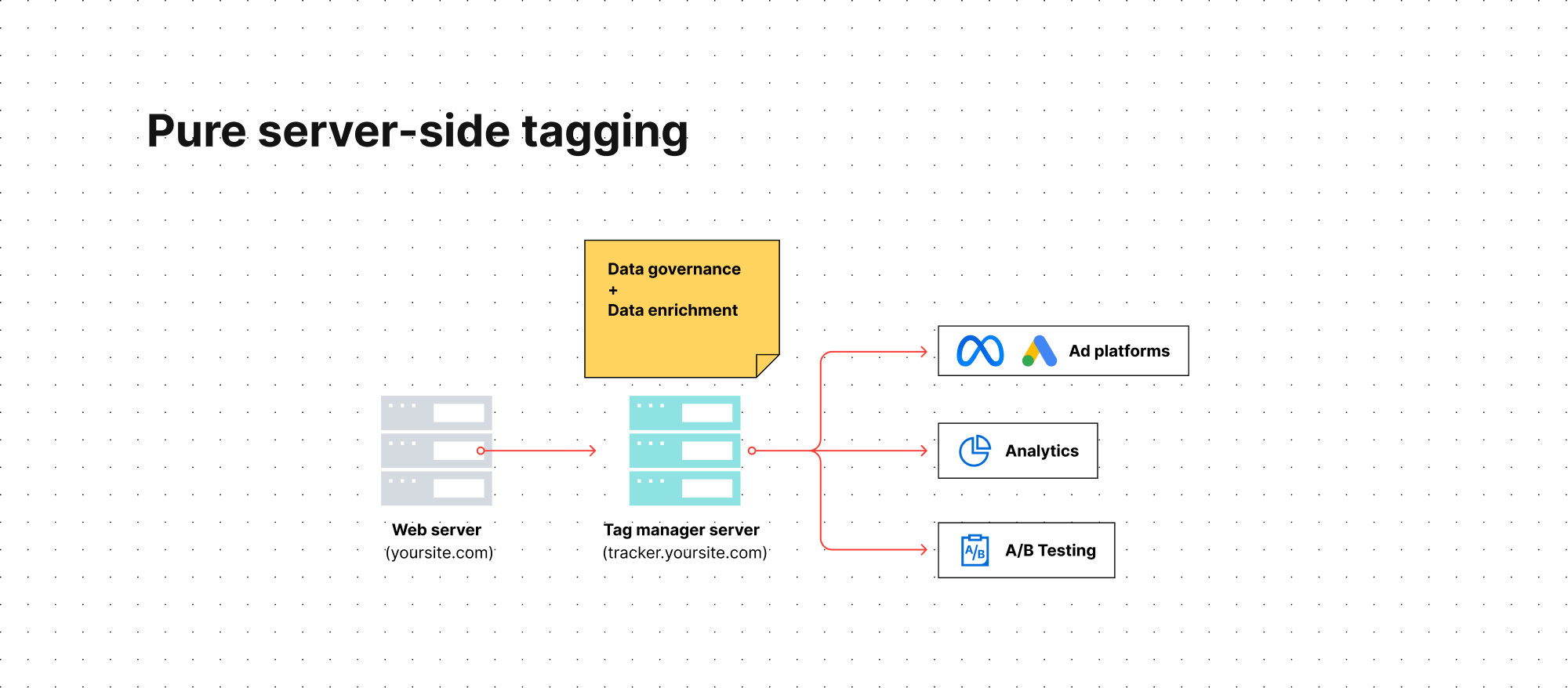
Par conséquent, vous obtenez un contrôle total sur les types de données que vous partagez avec vos outils marketing. Vous pouvez, par exemple, renforcer le respect de la confidentialité en évitant toute transmission des données personnelles à certaines plateformes ou en les hachant avant que les informations n’atteignent l’appareil final. Cette configuration vous permet également d’intégrer et d’enrichir votre ensemble de données, ce qui peut être utile pour améliorer la communication avec les plateformes publicitaires et assurer un suivi précis des conversions.
A noter, toutefois, que cette méthode ne représente pas la configuration par défaut des outils tels que Google Analytics 4 qui reposent sur une implémentation hybride côté serveur.
Le navigateur n’étant pas impliqué, les données collectées de cette manière sont beaucoup plus fiables et précises qu’avec le balisage hybride côté client et côté serveur.
Continuez la lecture pour en savoir plus sur les avantages et les particularités de cette méthode.
Exemples d’outils pour le suivi pur côté serveur : Google Analytics 4 avec GTM côté serveur en déploiement personnalisé et vos propres solutions.
Balisage hybride côté serveur
Balisage côté serveur proposé par Google Tag Manager ou Jentis est une méthode hybride de collecte des données.
Celle-ci partage de nombreux avantages avec le balisage pur côté serveur et présente moins de difficultés de mise en œuvre grâce aux produits et solutions prêts à l’emploi, assurés par les fournisseurs. Pour cette raison, la solution jouit d’une plus grande popularité que le déploiement pur côté serveur.
Cependant, ce qui la distingue est son approche hybride. En effet, la gestion des balises côté serveur repose fortement sur un composant côté client. Dans la configuration standard d’outils tels que Google Analytics 4, la demande de suivi commence avec un gestionnaire de balises côté client avant de passer à son homologue côté serveur.
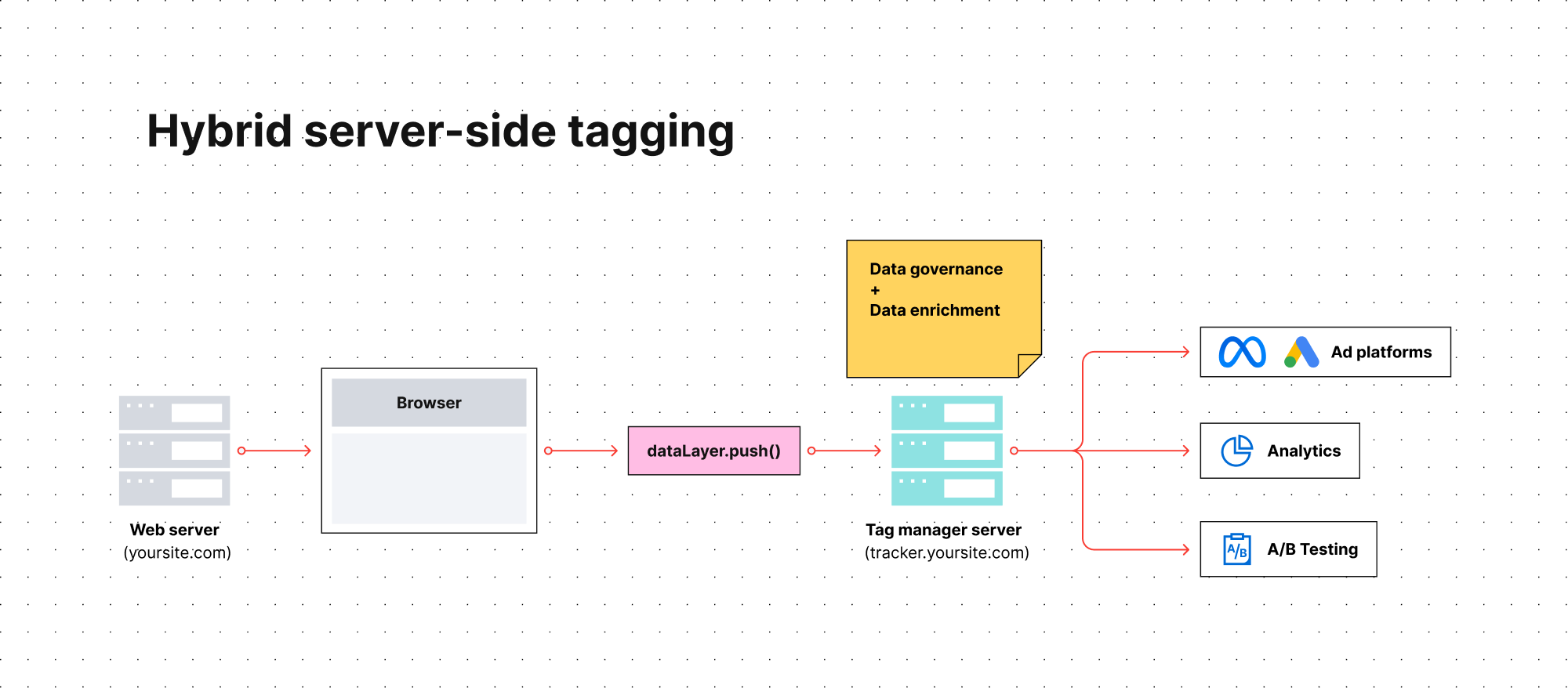
Résultat ? Malgré un meilleur contrôle des données, votre méthode de collecte peut toujours rencontrer des difficultés similaires à celles typiques pour le balisage traditionnel côté client.
Les avantages du balisage côté serveur
Gouvernance des données
En gérant les balises côté serveur, les organisations ont un meilleur contrôle sur les données collectées et partagées. Par exemple, vous pouvez décider de masquer, supprimer ou anonymiser des éléments de données spécifiques, tels que des adresses IP, avant d’envoyer des données à une plateforme tierce particulière. Cela réduit le risque d’accès non autorisé aux données.
Données « nettoyées »
Le balisage côté serveur vous permet de filtrer les données inutiles ou redondantes avant qu’elles n’atteignent les fournisseurs. Résultat ? Des jeux de données mieux nettoyés et plus précis.

« Le balisage côté serveur vous dote de plus de contrôle sur les données avant leur envoi à la destination finale. La méthode vous permet de filtrer ou de hacher des informations spécifiques, telles que les PII. Elle contribue également à enrichir les données avec des informations que vous ne souhaitez pas rendre visibles dès le départ, comme les marges de vos produits. »
Timo Dechau
Fondateur, ingénieur de suivi et d’analyse chez Deepskydata
Performances du site web améliorées
La méthode favorise la réduction du nombre de balises qui s’exécutent sur le site Web, améliorant ainsi les performances de votre site Web.
Enrichissement des données
Vous avez la possibilité d’enrichir les données entrantes avec des informations provenant de différents outils, tels que votre CRM ou votre système transactionnel.
Durée de vie des cookies prolongée
Les cookies étant définis à partir des sous-domaines de votre site Web, cette méthode augmente souvent leur durée de vie et vous permet de collecter des données plus fiables par rapport aux systèmes standard de gestion des balises côté client.
« Tout le monde peut bénéficier du suivi côté serveur, mais l’impact sur les petits sites Web ne serait pas assez important pour justifier le coût et les ressources nécessaires pour sa mise en place et maintenance. Meta, Pinterest, Google et d’autres grandes entreprises technologiques recommandent actuellement, ou devrais-je dire imposent aux spécialistes du marketing qu’ils mettent en œuvre le balisage côté serveur pour bénéficier au maximum des capacités de remarketing et de reciblage. Cette méthode est donc devenue essentielle pour eux. Si une organisation a atteint la maturité analytique et que les données sont utilisées pour des décisions critiques, investir dans la configuration côté serveur peut apporter des avantages significatifs. »
Anil Batra
Conseiller en données numériques et analyse, PDG d’Optizent
Considérations importantes pour le balisage côté serveur
Conformité en matière de confidentialité
Comme les autres méthodes, le balisage côté serveur nécessite le consentement des visiteurs pour collecter des données personnelles, telles que des identifiants uniques. De même, si vous décidez d’enrichir les données ou d’envoyer des données sur les conversions à différentes plateformes, vous aurez besoin d’un consentement distinct pour chacun de ces objectifs. Alors que l’anonymisation des données peut faciliter la collecte sans consentement, celle-ci limite considérablement la valeur des données.
Découvrez comment obtenir le consentement aux cookies côté serveur.
Mise en œuvre complexe
Le balisage côté serveur nécessite un système spécialisé de gestion des balises ainsi que l’installation et la maintenance d’un serveur ou d’une base de données basée sur le cloud. Cet effort exige un travail supplémentaire de la part des équipes techniques et s’avère encore plus complexe lorsque vous décidez de mettre en œuvre un balisage pur côté serveur.

« Le balisage côté serveur peut s’avérer une excellente solution pour les entreprises, leur permettant de surmonter certains obstacles à la collecte de données inhérents au suivi sur le navigateur, dont l’impact des bloqueurs de publicité et la suppression progressive des cookies tiers, pour n’en nommer que quelques-uns. Cependant, le processus d’apprentissage peut s’avérer exigeant et coûteux en raison des dépenses supplémentaires, dont par exemple l’emploi d’experts qui vont entretenir l’infrastructure. »
Hamza El Kharraz
Digital Analyst chez ANALYGO
Coûts
Cette méthode impose des coûts de serveur supplémentaires qui dépendent du volume de données traitées.
Assistance limitée
Avant d’investir dans la solution, assurez-vous que le balisage côté serveur est pris en charge par l’ensemble de vos outils. En effet, certains fournisseurs de marketing n’ont pas encore intégré de balises pour cette technologie.
Précision des données réduites (s’applique au balisage hybride côté serveur)
Le balisage hybride côté serveur repose toujours sur un composant côté client. Il est donc confronté à des défis similaires à ceux d’une configuration de gestionnaire de balises standard. Cela peut conduire à des données plus fragmentées par rapport aux méthodes qui utilisent une configuration pure côté serveur.
AVIS D’EXPERT
Timo Dechau
Fondateur, ingénieur de suivi et d’analyse chez Deepskydata
Je n’envisage que des cas d’utilisation limités pour le balisage côté serveur. Si vous utilisez une solution d’analyse qui vous donne moins de contrôle sur le type et la forme des données envoyées, pensez à utiliser Google Tag Manager côté serveur pour supprimer ou hacher ces informations. Bien que certains cas d’utilisation de l’enrichissement semblent également valides, je préfère réaliser l’enrichissement dans l’entrepôt de données.
Pensez au balisage côté serveur comme d’un autre bloc dans votre système. Assurez-vous qu’il est opérationnel 100 % du temps, car lorsqu’il est en panne, vous perdez vos données. En choisissant cette méthode de suivi, vous augmentez également la complexité de votre configuration. Identifier les problèmes de suivi et ajouter de nouveaux composants à celui-ci devient plus compliqué.
Outils et services de balisage côté serveur
- Google Server-Side Tag Manager (sGTM)
- Segment
- Adobe Analytics
- Jentis
Suivi côté serveur vs. Balisage côté serveur : une comparaison rapide
| Suivi pur côté serveur | Suivi hybride côté serveur | Balisage côté serveur pur | Balisage hybride côté serveur | Balisage côté client | Suivi côté client | |
|---|---|---|---|---|---|---|
Qualité et fiabilité des données | ||||||
Durée de vie des cookies prolongée | ||||||
Facilité d’utilisation | ||||||
Respect de la vie privée | Dépend de votre configuration | Dépend de votre configuration | Dépend de votre configuration | Dépend de votre configuration | Dépend de votre configuration | Dépend de votre configuration |
Possibilité d’envoyer des données à plusieurs endpoints |
Idées reçues sur le suivi et le balisage côté serveur
Les idées fausses sur le suivi et le balisage côté serveur conduisent à une mauvaise compréhension de leurs capacités et limites. Bien que ces méthodes puissent améliorer la fiabilité des données et résoudre certains problèmes côté client, elles ne constituent pas une solution universelle à tous les problèmes liés à la collecte de données. Voici des exemples de cas d’utilisation où le balisage et le suivi côté serveur ne seront pas ou ne devront pas être votre premier choix.
Passer au suivi côté serveur vous permet de contourner les choix utilisateurs et les régulations en matière de confidentialité
Le suivi et le balisage côté serveur vous aident à améliorer la qualité des données et à contourner les limites du suivi côté client. Or, bien que certains trackers côté serveur ne soient pas visibles dans les navigateurs, ceux-ci ne devraient pas être utilisés pour tromper les utilisateurs ou contourner les exigences de consentement pour la collecte de données. La conformité aux réglementations de confidentialité telles que le RGPD, le TDDDG et le PECR, ainsi que le respect des choix utilisateurs, sont essentiels pour maintenir la confiance des clients et établir des relations commerciales durables.
Le suivi côté serveur est une excellente alternative au suivi tiers
Contrairement à la croyance populaire, le passage au suivi côté serveur n’apporte pas de solutions à la dépréciation des cookies tiers : l’un des plus grands défis marketing de nos jours. Bien que le suivi et le balisage côté serveur puissent améliorer la qualité de vos données internes, ils ne répondent pas directement aux préoccupations liées aux cookies tiers.
Ces derniers étant progressivement éliminés, le reciblage des visiteurs anonymes sur différents sites devient de plus en plus difficile. L’alternative proposée par le balisage côté serveur consiste à envoyer des données personnelles, telles que des emails ou des adresses hachés à des plateformes publicitaires, mais sans impliquer le navigateur.
Alors que cette méthode puisse améliorer considérablement l’exactitude de vos données, elle reste illégale si utilisée sans le consentement explicite de l’utilisateur. Obtenir ce consentement peut être extrêmement difficile, ce qui en fait un obstacle difficile à franchir, malgré les avantages potentiels.
Pour en savoir plus sur les meilleures stratégies de données respectueuses de la vie privée pour un “avenir sans cookies”, consultez l’article : Voici tout ce qu’il faut en savoir sur la fin des cookies tiers.
Comment mettre en œuvre le suivi et le balisage côté serveur avec Piwik PRO
Le suivi et le balisage côté serveur offrent des alternatives robustes aux méthodes traditionnelles côté client, améliorant la qualité, la sécurité et le contrôle des données. Cependant, la mise en œuvre de ces solutions nécessite une expertise technique et la conformité aux réglementations en matière de confidentialité.
Piwik PRO Analytics Suite est une plateforme axée sur la confidentialité qui offre des capacités d’analyse avancées. La suite se compose de quatre modules étroitement intégrés : Analytics, Tag Manager, Consent Manager et Customer Data Platform. Elle se connecte facilement à votre ensemble technologique, vous permettant d’intégrer et d’activer des données dans tous vos outils marketing.
Voici les méthodes que vous pouvez adopter pour le suivi et le balisage côté serveur avec Piwik PRO :
- Suivi pur côté serveur – possible grâce aux API et SDK Piwik PRO.
- Balisage côté serveur avec sGTM (bientôt dispobible) – une solution convenable pour les entreprises qui souhaitent associer Piwik PRO Analytics à Google Tag Manager ; disponible dans les plans Business et Enterprise.
- Suivi hybride côté serveur avec un collecteur de première partie – il s’agit d’une excellente solution pour les entreprises qui cherchent à déplacer leur suivi analytique côté serveur. Grâce à l’intégration native avec Piwik PRO Consent Manager et Cookie Information CMP, vous pourrez ajuster votre suivi aux préférences de confidentialité de vos visiteurs. Cela vous permet également d’utiliser diverses méthodes d’anonymisation des données pour assurer que vous collectiez des données précieuses même lorsque les visiteurs ne consentent pas au suivi. Option disponible dans le plan Enterprise.
- Balisage hybride côté serveur facilité grâce à l’intégration avec Jentis – une alternative plus respectueuse de la vie privée mais toujours puissante et qui ne dépend pas de produits Google. Elle est disponible dans les plan Business et Enterprise.
Le plan Enterprise pour Piwik PRO Analytics Suite est livré avec un support et un service client dédiés pour vous aider à tirer le meilleur parti de votre projet de suivi ou de balisage côté serveur. Si vous souhaitez en savoir plus sur les possibilités de suivi côté serveur avec Piwik PRO, n’hésitez pas à nous contacter.
Rubrique FAQ
Qu’est-ce que l’analyse suivi côté serveur ?
Le suivi analytique côté serveur est une méthode de collecte de données dans laquelle tout le suivi et la collecte de données à partir de votre site Web ou de votre application se font sur un serveur plutôt que dans votre navigateur Web. Le serveur envoie ensuite ces données à votre plateforme d’analyse pour générer des rapports et des tableaux de bord.
Qu’est-ce que le balisage côté serveur ?
Le balisage côté serveur est une méthode de collecte de données qui utilise un serveur dédié pour gérer et héberger les balises de suivi, puis envoie les données aux outils marketing. Cette configuration crée un tampon entre votre site Web et les fournisseurs tiers, ce qui vous permet de mieux contrôler les types de données que vous partagez avec chaque plateforme marketing.
Le suivi côté serveur, est-il une méthode sans cookies ?
Le suivi analytique côté serveur est souvent considéré exempt de cookies car il ne dépend pas des cookies du navigateur pour suivre les actions des utilisateurs. Cependant, de nombreuses solutions de balisage et de suivi côté serveur, comme sGTM, Matomo, Piwik PRO ou Jentis, utilisent toujours des cookies, mais d’une manière différente par rapport au suivi côté client.
Qu’est-ce que l’analyse des journaux ?
L’analyse des journaux, souvent considérée comme l’une des premières méthodes de suivi côté serveur, est un processus d’analyse des données provenant des journaux de votre site Web. Cette approche vous permet d’importer des journaux côté serveur à l’aide d’un logiciel spécialisé qui fonctionne avec le serveur Web. Ainsi, vous pouvez récupérer des enregistrements qui correspondent à des critères spécifiques, identifier des tendances courantes et analyser des schémas.
Les informations collectées via les journaux du serveur sont, toutefois, relativement limitées par rapport aux données collectées via JavaScript côté client. Les journaux du serveur manquent d’informations essentielles tels que les plugins du navigateur, les résolutions d’écran et les titres de page qui peuvent être utiles pour votre analyse. De plus, l’identification des visiteurs devient difficile car les journaux du serveur ne conservent pas d’informations sur les identifiants stockés dans les cookies du navigateur utilisateur.

